Introdução à análise de grafos em Python com pandas e networkx
A análise de grafos não é um novo ramo da ciência de dados, ainda que não seja o método usual de "aplicar" o que os cientistas de dados aplicam hoje.
No entanto, existem algumas coisas malucas que os gráficos podem fazer. Os casos de uso clássicos variam de detecção de fraude a recomendações ou análise de redes sociais. Um caso de uso não clássico na PNL lida com a extração de tópicos (grafos de palavras).
Você tem um banco de dados de clientes e gostaria de saber como eles estão conectados uns aos outros. Especialmente, você sabe que alguns clientes estão envolvidos em estruturas complexas de fraude, mas a visualização dos dados em um nível individual não traz evidências de fraude. Os fraudadores se parecem com outros clientes habituais.
Trabalhar em conexões entre usuários pode mostrar muito mais informações do que se você simplesmente visualizar dados brutos. Especificamente, recursos que não seriam considerados arriscados para um modelo de pontuação baseado em aprendizado de máquina usual (número de telefone, endereço de e-mail, endereço residencial) podem se tornar recursos de risco em um modelo de pontuação baseado em grafo.
Exemplo: três indivíduos com os mesmos números de telefone, conectados a outras pessoas com os mesmos endereços de e-mail, são incomuns e potencialmente arriscados. O valor do número de telefone não fornece nenhuma informação em si (portanto, mesmo o melhor modelo de aprendizagem profunda não captura nenhum valor), mas o fato de os indivíduos estarem conectados através dos mesmos valores de números de telefone ou endereços de e-mail pode ser sinônimo de risco.
Vamos fazer isso em Python.

Ok, os dados foram carregados em df. Agora, vamos fazer algumas preparações. Você precisa conectar pessoas (representadas por seu ID) que tenham o mesmo número de telefone e o mesmo e-mail. Primeiro começamos com o número de telefone:
Os dados serão os seguintes:

Temos algumas conexões aqui, mas duas questões:
Vamos limpar isso:

Agora vamos visualizar nossos dados.
O simples nx.draw (G) nos dá o seguinte:
 Bacana né?
Bacana né?
Padrão bastante interessante! Mas espere, não podemos ver quem são os indivíduos e quais são os links. Vamos personalizá-lo:
Boa! 4 pessoas conectadas, por 2 números de telefone diferentes e 1 endereço de e-mail.
Voilà, mais algumas investigações devem seguir, mas você conseguiu criar um padrão de detecção de fraude!

Se você é orientado por negócios e espera que alguns especialistas usem o que você fez, seu próximo foco deve ser:

No entanto, existem algumas coisas malucas que os gráficos podem fazer. Os casos de uso clássicos variam de detecção de fraude a recomendações ou análise de redes sociais. Um caso de uso não clássico na PNL lida com a extração de tópicos (grafos de palavras).
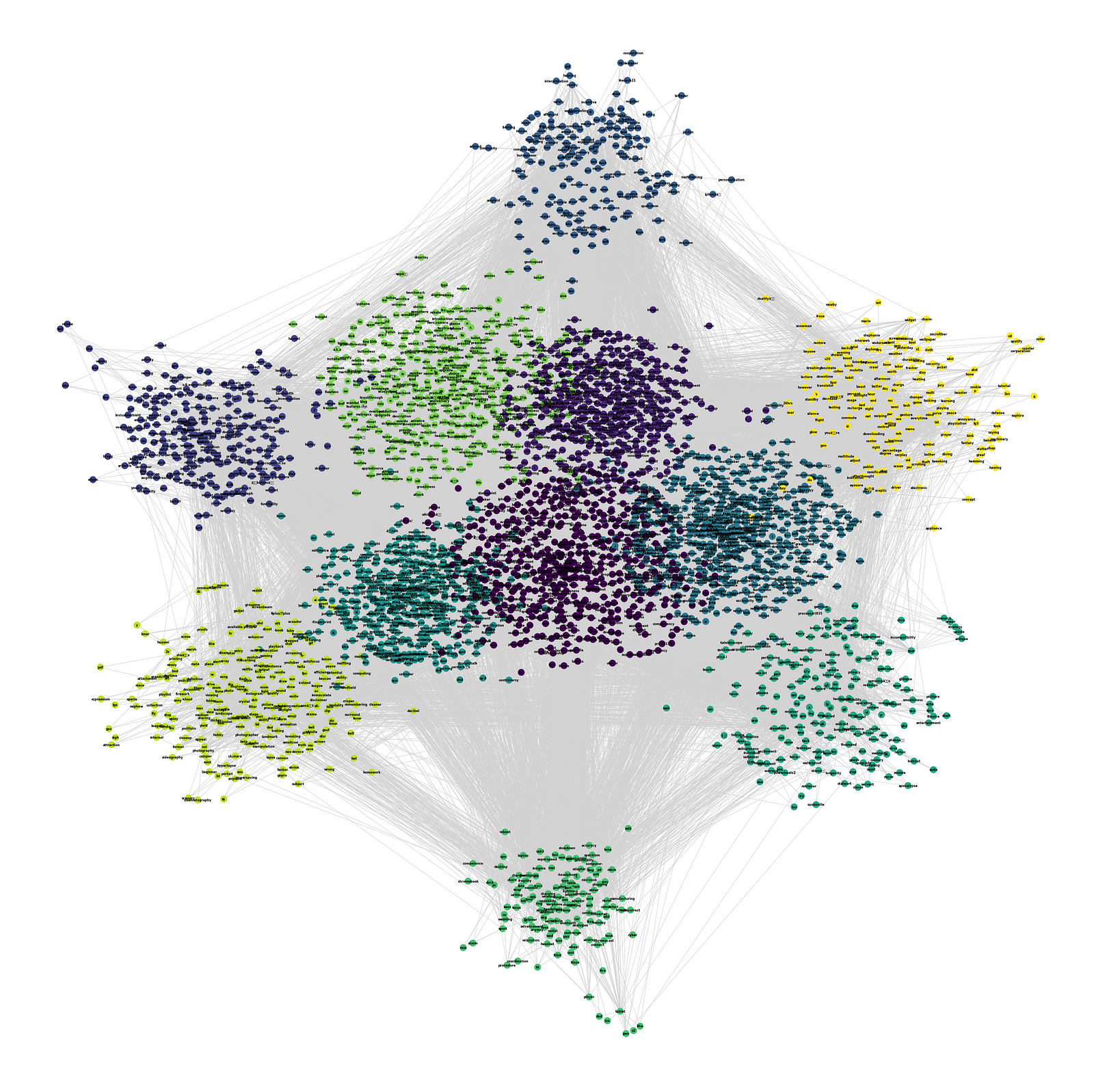 |
| visualização de um grafo de palavras, onde cada comunidade representa um tópico diferente |
Considere um caso de uso de detecção de fraude
Você tem um banco de dados de clientes e gostaria de saber como eles estão conectados uns aos outros. Especialmente, você sabe que alguns clientes estão envolvidos em estruturas complexas de fraude, mas a visualização dos dados em um nível individual não traz evidências de fraude. Os fraudadores se parecem com outros clientes habituais.
Trabalhar em conexões entre usuários pode mostrar muito mais informações do que se você simplesmente visualizar dados brutos. Especificamente, recursos que não seriam considerados arriscados para um modelo de pontuação baseado em aprendizado de máquina usual (número de telefone, endereço de e-mail, endereço residencial) podem se tornar recursos de risco em um modelo de pontuação baseado em grafo.
Exemplo: três indivíduos com os mesmos números de telefone, conectados a outras pessoas com os mesmos endereços de e-mail, são incomuns e potencialmente arriscados. O valor do número de telefone não fornece nenhuma informação em si (portanto, mesmo o melhor modelo de aprendizagem profunda não captura nenhum valor), mas o fato de os indivíduos estarem conectados através dos mesmos valores de números de telefone ou endereços de e-mail pode ser sinônimo de risco.
Vamos fazer isso em Python.
Configurando os dados, limpando e criando nosso grafo

Então vamos ler os dados a partir de um pandas DataFrame (que é basicamente uma tabela do Excel em Python).
import pandas as pd
df = pd.DataFrame({'ID':[1,2,3,4,5,6],
'Nome':['Fabiano', 'Jesse', 'James', 'Jean', 'James', 'Tesouro'],
'Sobrenome': ['Adelino', 'Porchat', 'Daler', 'Gleiser', 'Ribeiro', 'Da Mamãe'],
'Telefone': ['11 12345 6789', '11 12345 7657', '11 12345 6789', '11 99999 9999', '11 12345 7845', '11 12345 7845'],
'Email': ['fabiano.adelino@intelekts.com.br', 'jesse@clicouvendas.com.br', 'james@intelekts.com.br', pd.np.nan, 'james@intelekts.com.br', pd.np.nan]})
Ok, os dados foram carregados em df. Agora, vamos fazer algumas preparações. Você precisa conectar pessoas (representadas por seu ID) que tenham o mesmo número de telefone e o mesmo e-mail. Primeiro começamos com o número de telefone:
column_edge = 'Telefone'
column_ID = 'ID'
data_to_merge = df[[column_ID, column_edge]].dropna(subset=[column_edge]).drop_duplicates() # seleciona colunas, tira os NaN
# Para criar conexões entre pessoas que têm o mesmo número,
# junte dados na coluna "ID".
data_to_merge = data_to_merge.merge(
data_to_merge[[column_ID, column_edge]].rename(columns={column_ID:column_ID+"_2"}),
on=column_edge
)
data_to_merge
Os dados serão os seguintes:
Temos algumas conexões aqui, mas duas questões:
- Os indivíduos estão conectados consigo mesmos;
- Quando X está conectado com Y, Y também está conectado com X, e nós temos duas linhas para a mesma conexão.
Vamos limpar isso:
# Juntando os dados a si mesmos, as pessoas terão uma conexão consigo mesmas.
# Remova as conexões, para manter apenas as pessoas conectadas que são diferentes.
d = data_to_merge[~(data_to_merge[column_ID]==data_to_merge[column_ID+"_2"])] \
.dropna()[[column_ID, column_ID+"_2", column_edge]]
# Para evitar a contagem de duas vezes as mesmas conexões (pessoa 1 conectada a pessoa 2 e pessoa 2 conectada a pessoa 1)
# forçamos o primeiro ID a ser "inferior" a ID_2
d.drop(d.loc[d[column_ID+"_2"]d
Ótimo, 1 e 3 estão conectados e 5 e 6 também. Fazemos o mesmo com endereços de e-mail (código completo compartilhado no final do artigo). Agora vamos criar um gráfico. Compartilharei apenas a parte simples do código aqui, pois é um pouco complicado adicionar tipos diferentes de links.
import networkx as nx G = nx.from_pandas_edgelist(df=d, source=column_ID, target=column_ID+'_2', edge_attr=column_edge) G.add_nodes_from(nodes_for_adding=df.ID.tolist()) G.nodes()
Agora vamos visualizar nossos dados.
Visualização de gráfico com networkx
O simples nx.draw (G) nos dá o seguinte:

Padrão bastante interessante! Mas espere, não podemos ver quem são os indivíduos e quais são os links. Vamos personalizá-lo:
Boa! 4 pessoas conectadas, por 2 números de telefone diferentes e 1 endereço de e-mail.
Voilà, mais algumas investigações devem seguir, mas você conseguiu criar um padrão de detecção de fraude!
Próximos passos para executar um app em produção
Vamos recapitular o que fizemos:- Criação de um gráfico do nosso banco de dados de usuários;
- Visualização personalizada que nos ajuda a ver padrões estranhos.
Se você é orientado por negócios e espera que alguns especialistas usem o que você fez, seu próximo foco deve ser:
- Automação do processo de encontrar várias pessoas conectadas, ou detecção de padrões de risco;
- Automação do processo de criação de visualizações e criação de painel personalizado com visualização de gráficos e dados brutos.
Detecção de padrões de risco
Duas maneiras de proceder aqui:
- Ir de pessoas que você considera arriscadas (ou que você detectou como fraudadores) e verificar suas relações com outros indivíduos. Para se relacionar com Machine Learning, seria uma espécie de método “supervisionado”. Para ir além, você também pode começar com uma pontuação de Aprendizado de Máquina, identificar os nós com a pontuação mais alta e procurar suas conexões no grafo para capturar mais nós.
- Identifique padrões incomuns (muitas conexões, rede densa ...). Este seria o método "não supervisionado" semelhante à detecção de anomalias/outliers.
No nosso exemplo, não conhecemos os fraudadores, por isso vamos para o segundo método.
O Networkx tem algoritmos já implementados para fazer exatamente isso: degree (), centrality (), pagerank (), connected_components () ... deixo que você ache a melhor forma como definir matematicamente o risco.
Criando visualizações e automatizando análises para o negócio
Vai parecer old school para a maioria dos cientistas de dados, mas uma maneira rápida de fazer isso seria no Excel.
O pacote xlsxwriter ajuda você a colar dados do gráfico de pessoas arriscadas e colar a imagem do gráfico que criamos diretamente no arquivo do Excel. Você receberá um painel para cada rede arriscada assim:

Para cada rede potencialmente arriscada, você automatizaria essa criação do painel, enviaria para os especialistas e os deixaria avaliar/confirmar o risco.
Você poderia adicionar algumas métricas no painel: número de pessoas envolvidas, número de números de telefone diferentes, endereços de e-mail, pontuação de ML de cada nó ...
Espero que você tenha achado este artigo útil, considere compartilha-lo em suas redes!!!








Nenhum comentário:
Postar um comentário