[Aprenda Time Series] - Processamento dos dados e visualização
A série temporal é uma sequência de observações indexadas em intervalos de tempo equidistantes. Portanto, a ordem e a continuidade devem ser mantidas em qualquer série temporal.
O conjunto de dados que usaremos é uma série temporal multivariada com dados horários de aproximadamente um ano, para a qualidade do ar em uma cidade italiana significativamente poluída. O conjunto de dados pode ser baixado do link abaixo - https://archive.ics.uci.edu/ml/datasets/air+quality.
É necessário ter certeza de que:
- A série temporal é igualmente espaçada e não há valores redundantes ou lacunas nela.
- Caso a série temporal não seja contínua, podemos aumentar ou diminuir a resolução.
import pandas
df = pandas.read_csv("AirQualityUCI.csv", sep = ";", decimal = ",")
df = df.iloc[ : , 0:14]

Para pré-processar a série temporal, certificamo-nos de que não há valores NaN (NULL) no conjunto de dados; se houver, podemos substituí-los por 0 ou valores médios ou precedentes ou sucessivos. Substituir é uma escolha preferida em vez de descartar para que a continuidade da série temporal seja mantida. No entanto, em nosso conjunto de dados, os últimos valores parecem ser NULL e, portanto, a eliminação não afetará a continuidade.

Depois de verificado os valores NaN, temos:

As séries temporais geralmente são plotadas como gráficos de linha em relação ao tempo. Para isso, vamos combinar a coluna de data e hora e convertê-la em um objeto datetime a partir de strings. Isso pode ser feito usando a biblioteca datetime.
Convertendo em objeto datetime

Vamos ver como algumas variáveis, como a temperatura, mudam com a mudança no tempo.
Mostrando plotagens

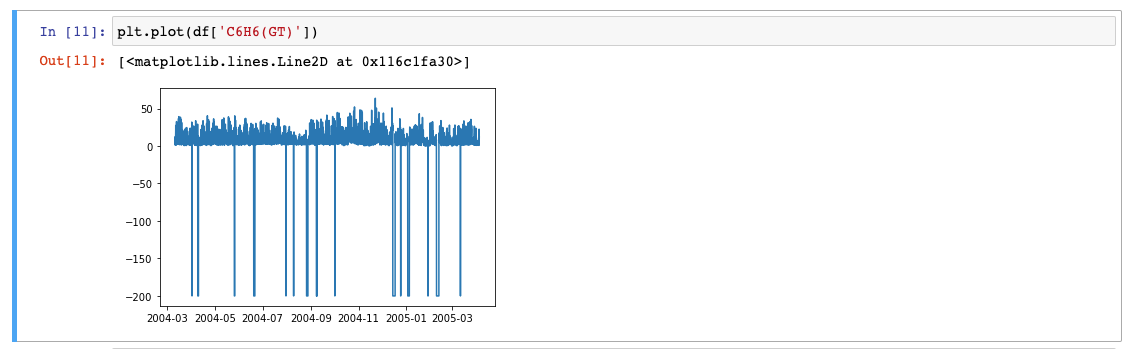
Mostrando BoxPlots

![[Aprenda Time Series] - Processamento dos dados e visualização](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhOhHb_i8vEbuAaFq7GRb0cNofMt7CGnB5ZMFRvVhLE-zehlHRJbe3MRMeC7aAaLeiy7_bXmlR1pf6bGi3k7wk2Fj22Goexmp6-P9NommsSIfV1gnFRhC4Yxxi4HI3ascw7ifu78CcTPw/s72-w640-c-h190/Screen+Shot+2021-01-04+at+10.43.35.png)







Nenhum comentário:
Postar um comentário