Classificando Tweets para Análise de Sentimento: Detectando se o Tweet é racista ou sexista
Execute a classificação de texto em Python

Recentemente, embarquei em um projeto de estudo para realizar a classificação de sentimentos em alguns comentários de clientes. Esta foi a primeira vez que trabalhei com dados de texto para aprendizado de máquina e achei muito difícil começar com uma área tão complexa.
Eu queria escrever um guia para que qualquer pessoa nova em processamento de linguagem natural (PNL) em Python conseguissem obter uma rápida visão geral do processo de ponta a ponta sem ter que mergulhar em todas as complexidades logo no início.
Este post é para qualquer um que gostaria de usar algum código para realizar uma tarefa de PNL em Python sem entrar em todos os detalhes. Meu estilo de aprendizado preferido é colocar as coisas em perspectiva primeiro e, em seguida, mergulhar nas porcas e parafusos de como tudo funciona. Espero que isso ajude os outros com um estilo de aprendizado similar.
Os dados
Para este post, vou usar um conjunto de dados retirado do site do Analytics Vidhya, que pode ser baixado aqui. Este é um bom e simples conjunto de dados para praticar e tem a vantagem adicional de fazer parte de uma competição contínua com uma tabela de classificação. Assim, você pode ter uma ideia rápida do desempenho do seu fluxo de trabalho escolhido.
O conjunto de dados consiste em teste e treino. O conjunto de treinamento compreende uma lista de 31.962 tweets, um id correspondente e um rótulo 0 ou 1 para cada tweet. O sentimento específico que você é solicitado a identificar neste problema é se o tweet é racista ou sexista (nesse caso, ele será rotulado como 1).
Então, para começar, importei os conjuntos de dados e estou retornando algumas informações sobre eles.
import pandas as pd
train = pd.read_csv('train.csv')
print("Training Set:"% train.columns, train.shape, len(train))
test = pd.read_csv('test_tweets.csv')
print("Test Set:"% test.columns, test.shape, len(test))
Limpeza dos dados
A maioria dos dados de texto provavelmente precisará de algum processamento para que o algoritmo de aprendizado de máquina escolhido tenha um bom desempenho. Nesse caso, cada documento de texto é um tweet e, portanto, conterá muitos caracteres que não serão significativos para nenhum algoritmo de aprendizado de máquina. Você pode ver abaixo apenas visualizando as primeiras linhas dos dados que os tweets contêm caracteres como #, @ e sinais de pontuação.
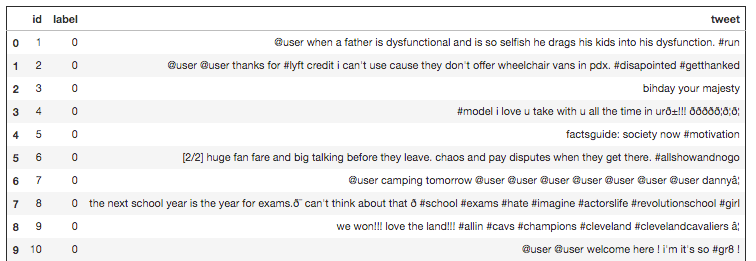
Para remover esses eu estou usando a biblioteca python re, isso fornece operações de correspondência de expressão regular. A seguinte função limpa com sucesso a maioria desses caracteres. Além disso, esta função transforma tudo em minúsculas.
Isso geralmente é uma boa ideia, pois muitas ferramentas de classificação de texto contam com a contagem das ocorrências de palavras. Se ambas as versões maiúsculas e minúsculas da mesma palavra forem encontradas no texto, o algoritmo as contará como palavras diferentes, embora o significado seja o mesmo.
Claro que isso significa que, onde as versões em maiúsculas de uma palavra existem, isso tem um significado diferente. Por exemplo, a empresa Apple vs apple (a fruta). Isso pode resultar em pior desempenho para alguns conjuntos de dados. Esta é uma área da PNL onde você pode experimentar métodos diferentes para ver como eles afetam o desempenho geral do modelo.
import re
def clean_text(df, text_field):
df[text_field] = df[text_field].str.lower()
df[text_field] = df[text_field].apply(lambda elem: re.sub(r"(@[A-Za-z0-9]+)|([^0-9A-Za-z \t])|(\w+:\/\/\S+)|^rt|http.+?", "", elem))
return df
test_clean = clean_text(test, "tweet") train_clean = clean_text(train, "tweet"
A saída após a limpeza se parece com a imagem abaixo. Não é perfeito, mas podemos ver como ele se comporta mais tarde em nosso modelo.

Se contarmos o número de tweets de cada etiqueta, podemos ver que há um número significativamente maior de tweets rotulados como 0. De fato, apenas 7% são classificados como sexistas/racistas. Isso é problemático, pois se fornecermos um algoritmo com esses dados, há uma grande chance de que ele seja padronizado para prever todos os rótulos como 0.
Existem vários métodos que você pode usar para lidar com isso. Uma abordagem é usar tanto upsampling quanto downsampling. No caso de upsampling usamos uma função que toma repetidamente amostras, com substituição, da classe minoritária até que a classe seja do mesmo tamanho que a maioria. Com substituição significa que a mesma amostra pode ser usada várias vezes.
Lidando com classes desequilibradas
Se contarmos o número de tweets de cada etiqueta, podemos ver que há um número significativamente maior de tweets rotulados como 0. De fato, apenas 7% são classificados como sexistas/racistas. Isso é problemático, pois se fornecermos um algoritmo com esses dados, há uma grande chance de que ele seja padronizado para prever todos os rótulos como 0.
Existem vários métodos que você pode usar para lidar com isso. Uma abordagem é usar tanto upsampling quanto downsampling. No caso de upsampling usamos uma função que toma repetidamente amostras, com substituição, da classe minoritária até que a classe seja do mesmo tamanho que a maioria. Com substituição significa que a mesma amostra pode ser usada várias vezes.
from sklearn.utils import resample
train_majority = train_clean[train_clean.label==0] train_minority = train_clean[train_clean.label==1]
train_minority_upsampled = resample(train_minority,
replace=True,
n_samples=len(train_majority),
random_state=123)
train_upsampled = pd.concat([train_minority_upsampled, train_majority])
train_upsampled['label'].value_counts()
Ao reduzir a resolução, usamos a mesma função para coletar amostras da classe majoritária, sem substituição, até que seja o mesmo tamanho da classe minoritária. Sem substituição significa que cada amostra é mostrada apenas uma vez.
train_majority = train_clean[train_clean.label==0]
train_minority = train_clean[train_clean.label==1]
train_majority_downsampled = resample(train_majority,
replace=True,
n_samples=len(train_minority),
random_state=123)
train_downsampled = pd.concat([train_majority_downsampled, train_minority])
train_downsampled['label'].value_counts()
Eu incluí isso no código acima. Eu tentei upsampling e downsampling e consegui um melhor resultado com upsampling então eu usei isso no meu fluxo de trabalho.
As máquinas não são capazes de ler textos da mesma maneira que os humanos. Para que um algoritmo de aprendizado de máquina determine padrões no texto, primeiro ele deve ser convertido em uma estrutura numérica. Uma das técnicas mais comuns para isso é chamada Bag of Words, ou BoW.
Um modelo de BoW divide as palavras em um texto em tokens, desconsiderando a gramática e a ordem das palavras. O modelo também conta a freqüência em que uma palavra ocorre no texto e atribui um peso proporcional a essa freqüência. A saída é uma matriz de frequências de termos em que cada linha representa o texto e cada coluna uma palavra no vocabulário.
O Sci-kit learn possui várias funções incorporadas para executar esse tipo de modelagem. Mas para este passo a passo eu vou estar usando uma das funções mais simples que é o CountVectoriser. Esta função funciona muito bem com as configurações padrão, então vou usá-las para a primeira iteração do meu modelo.
Como mencionado anteriormente no post, o modelo do BoW que estamos usando para processar o texto tem três etapas. O CountVectoriser realiza os dois primeiros, dividindo as palavras em tokens e contando a frequência. Podemos usar outra função scikit-learn chamada TfidfTransformer para aplicar a ponderação de frequência.
Em qualquer documento de texto, haverá várias palavras que aparecem com muita frequência, como eu, nós e obtenções. Se fôssemos construir um modelo sem pesar essas palavras, elas ofuscariam palavras menos frequentes durante o treinamento. Ao ponderarmos estas palavras de alta frequência, podemos atribuir, por exemplo, mais importância a palavras menos frequentes, mas talvez mais úteis.
Para simplicidade e reprodutibilidade, vou usar um sci-kit learn pipeline com um SGDClassifier. O código abaixo cria um objeto de pipeline que, quando usado, aplicará cada etapa aos dados.
CountVectoriser
As máquinas não são capazes de ler textos da mesma maneira que os humanos. Para que um algoritmo de aprendizado de máquina determine padrões no texto, primeiro ele deve ser convertido em uma estrutura numérica. Uma das técnicas mais comuns para isso é chamada Bag of Words, ou BoW.
Um modelo de BoW divide as palavras em um texto em tokens, desconsiderando a gramática e a ordem das palavras. O modelo também conta a freqüência em que uma palavra ocorre no texto e atribui um peso proporcional a essa freqüência. A saída é uma matriz de frequências de termos em que cada linha representa o texto e cada coluna uma palavra no vocabulário.
O Sci-kit learn possui várias funções incorporadas para executar esse tipo de modelagem. Mas para este passo a passo eu vou estar usando uma das funções mais simples que é o CountVectoriser. Esta função funciona muito bem com as configurações padrão, então vou usá-las para a primeira iteração do meu modelo.
TfidfTransformer
Como mencionado anteriormente no post, o modelo do BoW que estamos usando para processar o texto tem três etapas. O CountVectoriser realiza os dois primeiros, dividindo as palavras em tokens e contando a frequência. Podemos usar outra função scikit-learn chamada TfidfTransformer para aplicar a ponderação de frequência.
Em qualquer documento de texto, haverá várias palavras que aparecem com muita frequência, como eu, nós e obtenções. Se fôssemos construir um modelo sem pesar essas palavras, elas ofuscariam palavras menos frequentes durante o treinamento. Ao ponderarmos estas palavras de alta frequência, podemos atribuir, por exemplo, mais importância a palavras menos frequentes, mas talvez mais úteis.
Treinamento
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.pipeline import Pipeline from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfTransformer from sklearn.linear_model import SGDClassifier
pipeline_sgd = Pipeline([
('vect', CountVectorizer()),
('tfidf', TfidfTransformer()),
('nb', SGDClassifier()),
])
Antes de treinar o modelo, estou dividindo os dados de treinamento em um conjunto de treinamento e teste.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(train_upsampled['tweet'], train_upsampled['label'],random_state = 0)
O código abaixo ajusta o modelo aos dados de treinamento e calcula a pontuação F1.
model = pipeline_sgd.fit(X_train, y_train)
y_predict = model.predict(X_test)
from sklearn.metrics import f1_score
f1_score(y_test, y_predict)
Você notará acima que estou usando o conjunto de dados upsampled. Isso não é ideal, pois o modelo se desempenha muito melhor nos dados de treinamento do que nos novos dados de teste.
Por exemplo, nos dados de treinamento que obtive (após alguma otimização adicional), uma pontuação de F1 de 0,97, mas isso traduziu-se em uma pontuação de 0,75, uma vez que fiz minha submissão.
A redução da amostragem por causa do baixo volume de dados para a classe minoritária teve um desempenho ainda pior. Existem outras técnicas mais complexas para lidar com classes desequilibradas, como balanceamento de peso, mas esse assunto em si garante um outro post.
O processamento de linguagem natural é um assunto muito complexo e há muito mais que eu poderia abordar neste artigo. Meu objetivo aqui é fornecer informações e código suficientes para começar a usar seu primeiro modelo de classificação de texto.
A pontuação final não é tão ruim para uma primeira tentativa, mas há muito espaço para melhorias.
Existem muitos outros modelos além do BoW para processar os dados de texto, por exemplo, que podem funcionar melhor. Há mais trabalho que poderia ser feito com a nova biblioteca para limpar ainda mais os dados, e talvez a remoção de palavras de parada possa ajudar a melhorar ainda mais o modelo.
Então treine o modelo e se tiver dúvidas entre em contato!!!
Via: vickdata
Por exemplo, nos dados de treinamento que obtive (após alguma otimização adicional), uma pontuação de F1 de 0,97, mas isso traduziu-se em uma pontuação de 0,75, uma vez que fiz minha submissão.
A redução da amostragem por causa do baixo volume de dados para a classe minoritária teve um desempenho ainda pior. Existem outras técnicas mais complexas para lidar com classes desequilibradas, como balanceamento de peso, mas esse assunto em si garante um outro post.
O processamento de linguagem natural é um assunto muito complexo e há muito mais que eu poderia abordar neste artigo. Meu objetivo aqui é fornecer informações e código suficientes para começar a usar seu primeiro modelo de classificação de texto.
A pontuação final não é tão ruim para uma primeira tentativa, mas há muito espaço para melhorias.
Existem muitos outros modelos além do BoW para processar os dados de texto, por exemplo, que podem funcionar melhor. Há mais trabalho que poderia ser feito com a nova biblioteca para limpar ainda mais os dados, e talvez a remoção de palavras de parada possa ajudar a melhorar ainda mais o modelo.
Então treine o modelo e se tiver dúvidas entre em contato!!!
Via: vickdata








Nenhum comentário:
Postar um comentário